UUID
UUID 是 通用唯一识别码(Universally Unique Identifier)的缩写,是一种软件建构的标准,亦为开放软件基金会组织在分布式计算环境领域的一部分。其目的,是让分布式系统中的所有元素,都能有唯一的辨识信息,而不需要通过中央控制端来做辨识信息的指定。如此一来,每个人都可以创建不与其它人冲突的UUID。在这样的情况下,就不需考虑数据库创建时的名称重复问题。目前最广泛应用的UUID,是微软公司的全局唯一标识符(GUID),而其他重要的应用,则有Linux ext2/ext3文件系统、LUKS加密分区、GNOME、KDE、Mac OS X等等。另外我们也可以在e2fsprogs包中的UUID库找到实现。
UUID的标准形式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的32个字符,如:550e8400-e19b-41d4-a716-446655440000。
1、Version 1:基于时间的UUID基于时间的UUID通过计算当前时间戳、随机数和机器MAC地址得到。由于在算法中使用了MAC地址,这个版本的UUID可以保证在全球范围的唯一性。但与此同时,使用MAC地址会带来安全性问题,这就是这个版本UUID受到批评的地方。如果应用只是在局域网中使用,也可以使用退化的算法,以IP地址来代替MAC地址--Java的UUID往往是这样实现的(当然也考虑了获取MAC的难度)。
2、Version 2:DCE安全的UUIDDCE(Distributed Computing Environment)安全的UUID和基于时间的UUID算法相同,但会把时间戳的前4位置换为POSIX的UID或GID。这个版本的UUID在实际中较少用到。
3、Version 3:基于名字的UUID(MD5)基于名字的UUID通过计算名字和名字空间的MD5散列值得到。这个版本的UUID保证了:相同名字空间中不同名字生成的UUID的唯一性;不同名字空间中的UUID的唯一性;相同名字空间中相同名字的UUID重复生成是相同的。
4、Version 4:随机UUID根据随机数,或者伪随机数生成UUID。这种UUID产生重复的概率是可以计算出来的,但随机的东西就像是买彩票:你指望它发财是不可能的,但狗屎运通常会在不经意中到来。
5、Version 5:基于名字的UUID(SHA1)和版本3的UUID算法类似,只是散列值计算使用SHA1(Secure Hash Algorithm 1)算法。
UUID的优点:
通过本地生成,没有经过网络I/O,性能较快。
无序,无法预测他的生成顺序。(当然这个也是他的缺点之一)
UUID的缺点:
128位二进制一般转换成36位的16进制,太长了只能用String存储,空间占用较多。
不能生成递增有序的数字。
数据库主键自增
优点:
1、自增,趋势自增,作为聚集索引,提升查询效率。
2、节省磁盘空间。500W数据,UUID占5.4G,自增ID占2.5G。
3、查询,写入效率高:查询略优。写入效率自增ID是UUID的四倍。
缺点:
1、导入旧数据时,可能会ID重复,导致导入失败。
2、分布式架构,多个Mysql实例可能会导致ID重复。
PS:
1、单实例,单节点,由于InnoDB的特性,自增ID效率大于UUID。
2、20个节点一下小型分布式架构:为了实现快速部署,主键不重复,可以采用UUID。
3、20到200个节点:可以采用自增ID+步长的较快速方案。
4、200个以上节点的分布式架构:可以采用twitter的雪花算法全局自增ID。
Redis
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
优点:
1、不依赖于数据库,灵活方便,且性能优于数据库。
2、数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1、由于redis是内存的KV数据库,即使有AOF和RDB,但是依然会存在数据丢失,有可能会造成ID重复。
2、依赖于redis,redis要是不稳定,会影响ID生成。
Zookeeper
zookeeper做分布式一致性,没有啥好说的。
数据库分段+服务缓存ID
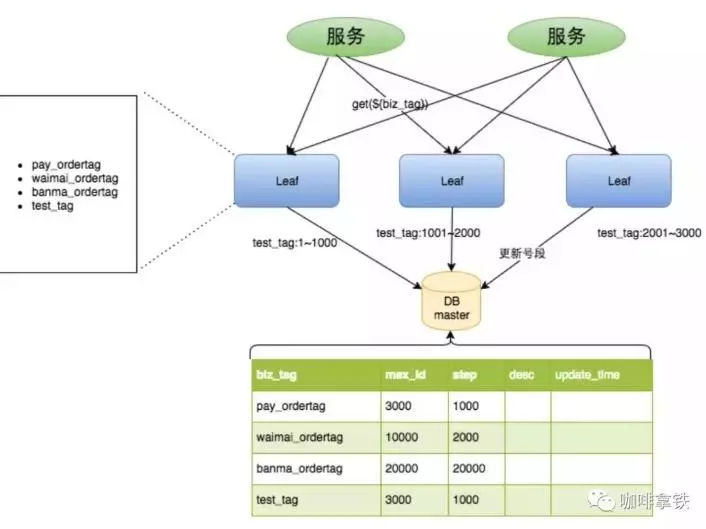
优点:
1、比主键递增性能高,能保证趋势递增。
2、如果DB宕机,proxServer由于有缓存依然可以坚持一段时间。
缺点:
1、和主键递增一样,容易被人猜测。
2、DB宕机,虽然能支撑一段时间但是仍然会造成系统不可用。
适用场景:需要趋势递增,并且ID大小可控制的,可以使用这套方案。
当然这个方案也可以通过一些手段避免被人猜测,把ID变成是无序的,比如把我们生成的数据是一个递增的long型,把这个Long分成几个部分,比如可以分成几组三位数,几组四位数,然后在建立一个映射表,将我们的数据变成无序。
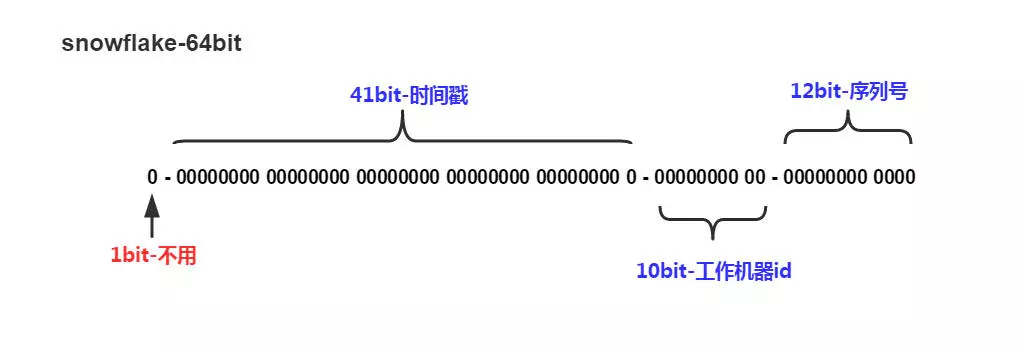
雪花算法-Snowflake
Snowflake是Twitter提出来的一个算法,其目的是生成一个64bit的整数:
雪花算法简单描述:
1、最高位是符号位,始终为0,不可用。
2、41位的时间序列,精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。
3、10位的机器标识,10位的长度最多支持部署1024个节点。
4、12位的计数序列号,序列号即一系列的自增id,可以支持同一节点同一毫秒生成多个ID序号,12位的计数序列号支持每个节点每毫秒产生4096个ID序号。