准确率(accuracy),精确率(Precision)和召回率(Recall)是信息检索,人工智能,和搜索引擎的设计中很重要的几个概念和指标。中文中这几个评价指标翻译各有不同,所以一般情况下推荐使用英文。
概念介绍
先假定一个具体场景作为例子。
假如某个班级有男生80人,女生20人,共计100人.目标是找出所有女生.
某人挑选出50个人,其中20人是女生,另外还错误的把30个男生也当作女生挑选出来了.
作为评估者的你需要来评估(evaluation)下他的工作
首先我们可以计算准确率(accuracy),其定义是:
对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。也就是损失函数是0-1损失时测试数据集上的准确率.
这样说听起来有点抽象,简单说就是,前面的场景中,实际情况是那个班级有男的和女的两类,某人(也就是定义中所说的分类器)他又把班级中的人分为男女两类。accuracy需要得到的是此君分正确的人占总人数的比例。很容易,我们可以得到:他把其中70(20女+50男)人判定正确了,而总人数是100人,所以它的accuracy就是70%(70 / 100).
由准确率,我们的确可以在一些场合,从某种意义上得到一个分类器是否有效,但它并不总是能有效的评价一个分类器的工作。举个例子,google抓取了argcv 100个页面,而它索引中共有10,000,000个页面,随机抽一个页面,分类下,这是不是argcv的页面呢?如果以accuracy来判断我的工作,那我会把所有的页面都判断为”不是argcv的页面”,因为我这样效率非常高(return false,一句话),而accuracy已经到了99.999%(9,999,900/10,000,000),完爆其它很多分类器辛辛苦苦算的值,而我这个算法显然不是需求期待的,那怎么解决呢?这就是precision,recall和f1-measure出场的时间了.
在说precision,recall和f1-measure之前,我们需要先需要定义TP,FN,FP,TN四种分类情况.
按照前面例子,我们需要从一个班级中的人中寻找所有女生,如果把这个任务当成一个分类器的话,那么女生就是我们需要的,而男生不是,所以我们称女生为”正类”,而男生为”负类”.
| 相关(Relevant),正类 | 无关(NonRelevant),负类 | |
|---|---|---|
| 被检索到(Retrieved) | true positives(TP 正类判定为正类,例子中就是正确的判定”这位是女生”) | false |
positives(FP 负类判定为正类,”存伪”,例子中就是分明是男生却判断为女生,当下伪娘横行,这个错常有人犯)
未被检索到(Not Retrieved)| false negatives(FN 正类判定为负类,”去真”,例子中就是,分明是女生,这哥们却判断为男生–梁山伯同学犯的错就是这个)| true negatives(TN 负类判定为负类,也就是一个男生被判断为男生,像我这样的纯爷们一准儿就会在此处)
通过这张表,我们可以很容易得到例子中这几个分类的值:TP=20,FP=30,FN=0,TN=50.

精确率”与“召回率”的关系
“精确率”与“召回率”虽然没有必然的关系(从上面公式中可以看到),然而在大规模数据集合中,这两个指标却是相互制约的。
由于“检索策略”并不完美,希望更多相关的文档被检索到时,放宽“检索策略”时,往往也会伴随出现一些不相关的结果,从而使准确率受到影响。
而希望去除检索结果中的不相关文档时,务必要将“检索策略”定的更加严格,这样也会使有一些相关的文档不再能被检索到,从而使召回率受到影响。
凡是涉及到大规模数据集合的检索和选取,都涉及到“召回率”和“精确率”这两个指标。而由于两个指标相互制约,我们通常也会根据需要为“检索策略”选择一个合适的度,不能太严格也不能太松,寻求在召回率和精确率中间的一个平衡点。这个平衡点由具体需求决定。
===================================
mAP 概念
P
precision,即 准确率 。
R
recall,即 召回率 。
PR曲线
即 以 precision 和 recall 作为 横纵轴坐标 的二维曲线。
一般来说,precision 和 recall 是 鱼与熊掌 的关系。下图即是 PR曲线:
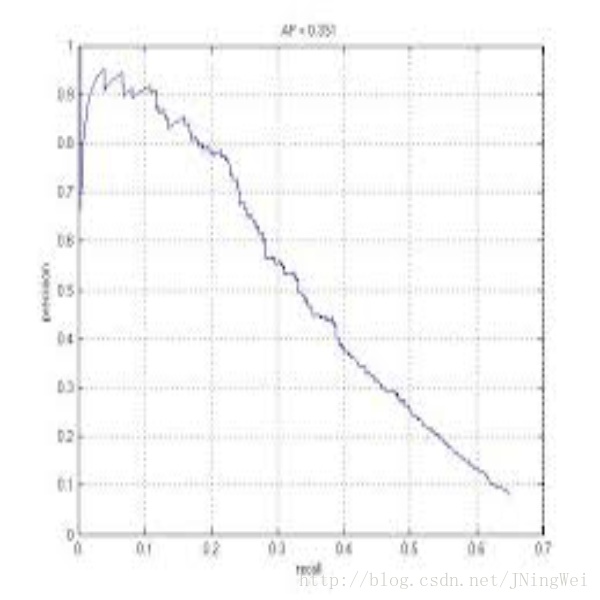
AP值
Average Precision,即 平均精确度 。
如何衡量一个模型的性能,单纯用 precision 和 recall 都不科学。于是人们想到,哎嘛为何不把 PR曲线下的面积 当做衡量尺度呢?于是就有了AP值 这一概念。这里的 average,等于是对 precision 进行 取平均 。
mAP值
Mean Average Precision,即 平均AP值 。
是对多个验证集个体 求 平均AP值 。如下图:
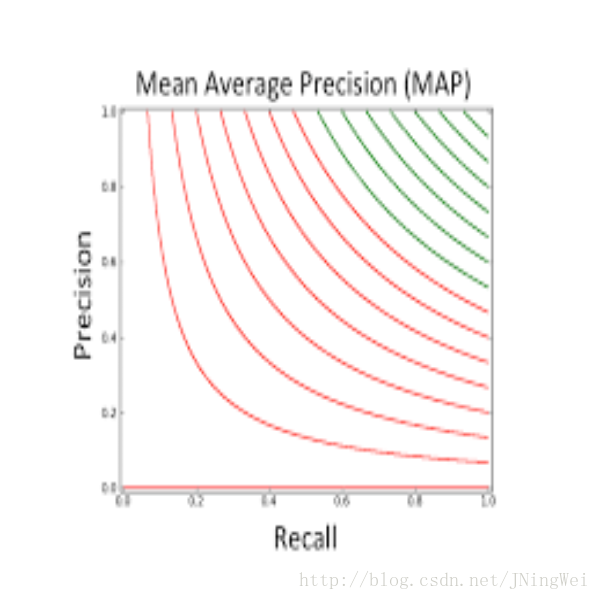
mAP 计算
公式
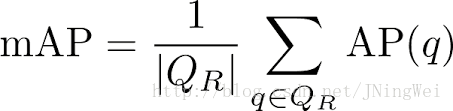
Code
def compute_ap(gt_boxes, gt_class_ids,
pred_boxes, pred_class_ids, pred_scores,
iou_threshold=0.5):
"""Compute Average Precision at a set IoU threshold (default 0.5).
Returns:
mAP: Mean Average Precision
precisions: List of precisions at different class score thresholds.
recalls: List of recall values at different class score thresholds.
overlaps: [pred_boxes, gt_boxes] IoU overlaps.
"""
# Trim zero padding and sort predictions by score from high to low
gt_boxes = trim_zeros(gt_boxes)
pred_boxes = trim_zeros(pred_boxes)
pred_scores = pred_scores[:pred_boxes.shape[0]]
indices = np.argsort(pred_scores)[::-1]
pred_boxes = pred_boxes[indices]
pred_class_ids = pred_class_ids[indices]
pred_scores = pred_scores[indices]
# Compute IoU overlaps [pred_boxes, gt_boxes]
overlaps = compute_overlaps(pred_boxes, gt_boxes)
# Loop through ground truth boxes and find matching predictions
match_count = 0
pred_match = np.zeros([pred_boxes.shape[0]])
gt_match = np.zeros([gt_boxes.shape[0]])
for i in range(len(pred_boxes)):
# Find best matching ground truth box
sorted_ixs = np.argsort(overlaps[i])[::-1]
for j in sorted_ixs:
# If ground truth box is already matched, go to next one
if gt_match[j] == 1:
continue
# If we reach IoU smaller than the threshold, end the loop
iou = overlaps[i, j]
if iou < iou_threshold:
break
# Do we have a match?
if pred_class_ids[i] == gt_class_ids[j]:
match_count += 1
gt_match[j] = 1
pred_match[i] = 1
break
# Compute precision and recall at each prediction box step
precisions = np.cumsum(pred_match) / (np.arange(len(pred_match)) + 1)
recalls = np.cumsum(pred_match).astype(np.float32) / len(gt_match)
# Pad with start and end values to simplify the math
precisions = np.concatenate([[0], precisions, [0]])
recalls = np.concatenate([[0], recalls, [1]])
# Ensure precision values decrease but don't increase. This way, the
# precision value at each recall threshold is the maximum it can be
# for all following recall thresholds, as specified by the VOC paper.
for i in range(len(precisions) - 2, -1, -1):
precisions[i] = np.maximum(precisions[i], precisions[i + 1])
# Compute mean AP over recall range
indices = np.where(recalls[:-1] != recalls[1:])[0] + 1
mAP = np.sum((recalls[indices] - recalls[indices - 1]) *
precisions[indices])
return mAP, precisions, recalls, overlaps